Introduction
The model works perfectly in the notebook.
Accuracy metrics look great. The data scientists are happy. Everyone’s excited to ship. Then it hits production and quietly starts degrading. Predictions drift. The pipeline breaks on data it’s never seen before. Nobody knows why because nobody set up monitoring. Retraining is a manual process that requires the original engineer who built it — who has since moved on to the next project.
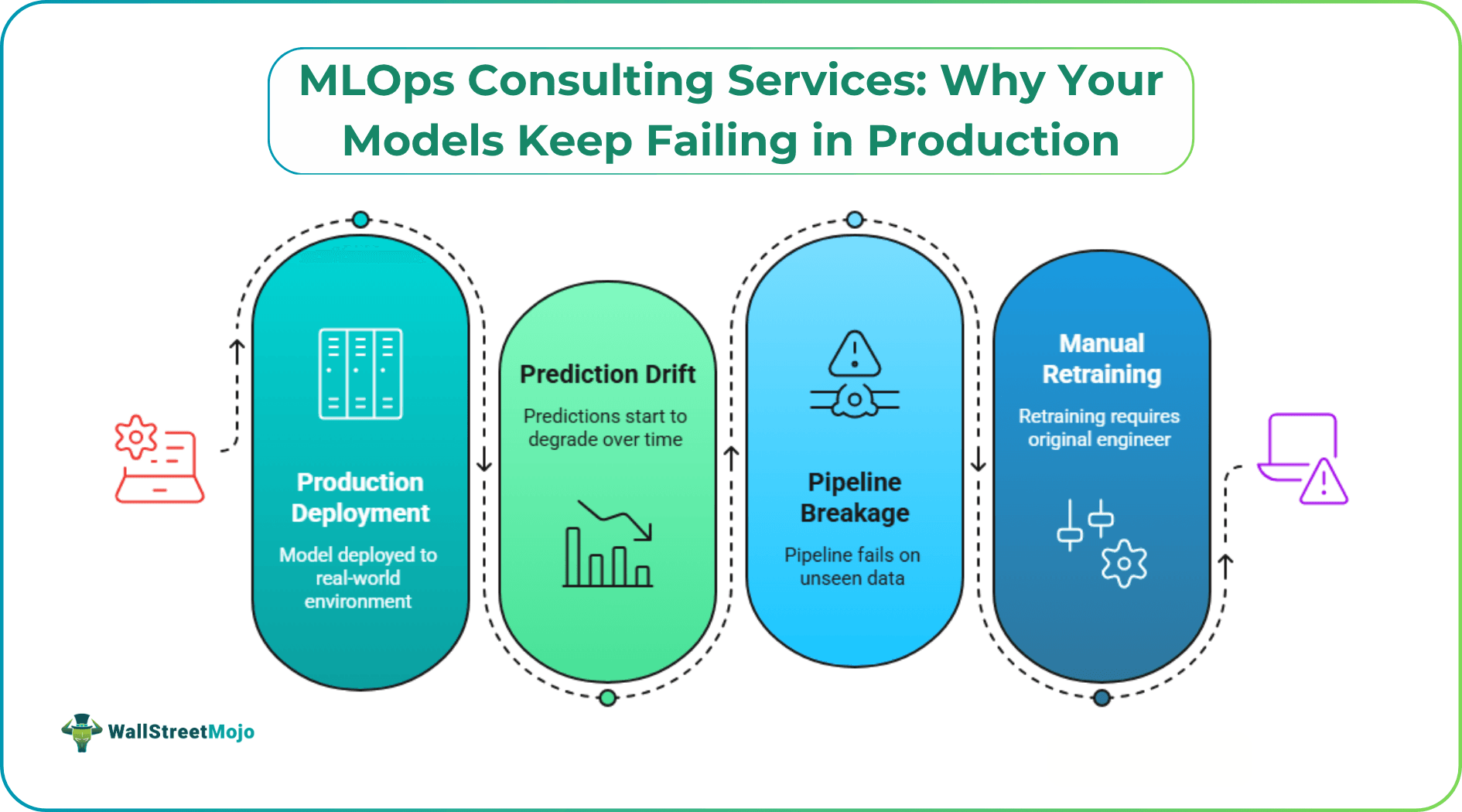
This is not an edge case. This is the default outcome for most ML deployments.
The gap between a model that works in a controlled environment and a model that holds up in the real world is where MLOps lives. And it’s where most teams are severely underinvested.
What MLOps Actually Is
Machine learning operations MLOps is the set of practices, tools, and infrastructure that makes ML models reliable in production. Not just deployed. Reliable. Monitored. Retrained when needed. Versioned properly. Reproducible. Governed.
It borrows from DevOps but it’s not the same thing. Code doesn’t drift. Models do. A software deployment either works or it doesn’t the failure is usually obvious. A model can fail gradually, silently, in ways that don’t trigger alerts but quietly degrade business outcomes for weeks before anyone notices.
That asymmetry is why MLOps requires its own discipline. And why MLOps consulting services exist because most engineering teams didn’t build these capabilities when they were building the models, and retrofitting them is harder than doing it right the first time.
The Production Gap Problem
Here’s the uncomfortable stat that gets cited a lot because it keeps being true: the majority of ML models that get built never make it to production. Of the ones that do, a significant portion fail within the first year.
The reasons cluster around the same issues every time:
| Failure Mode | What It Looks Like | Root Cause |
|---|---|---|
| Data drift | Predictions gradually degrade | Input data distribution shifts, model doesn’t adapt |
| Pipeline fragility | Model breaks on new data formats | No robust data validation layer |
| No monitoring | Nobody knows the model is failing | Monitoring was skipped or deprioritized |
| Manual retraining | Updates require original engineer | No automated retraining pipeline |
| Reproducibility issues | Can’t recreate the model that’s in production | No experiment tracking or model versioning |
| Governance gaps | Can’t audit decisions or track model lineage | No metadata management from the start |
None of these are unsolvable problems. They’re all symptoms of the same root cause: the model was built without the operational infrastructure around it.
What MLOps Consulting Services Actually Do
The consulting engagement looks different depending on where a team is starting from. But the core work falls into a few categories.
- Infrastructure assessment. Before building anything new, you need to understand what exists. What does the current ML pipeline look like? Where does it break? What’s the monitoring situation? What tools are already in use and what gaps exist? Most teams have more infrastructure than they realize it’s just inconsistent, undocumented, and not connected properly.
- Pipeline architecture and automation. The goal is a pipeline that runs without babysitting. Data ingestion, validation, feature engineering, training, evaluation, deployment each step automated, each failure handled gracefully, each output logged. Building this from scratch takes time. Retrofitting it onto an existing setup takes different kinds of time. Either way, it’s foundational.
- Model monitoring and alerting. This is where most teams have the biggest gap. You need to know when your model is drifting before your users do. That means monitoring input data distributions, prediction distributions, model performance metrics against ground truth when it’s available, and infrastructure health. Setting up meaningful alerts ones that fire when something’s actually wrong, not constantly or never is more nuanced than it sounds.
- Experiment tracking and model registry. Every experiment should be logged. Every model version should be tracked. The model in production should be traceable back to the data it was trained on, the hyperparameters used, and the evaluation results that justified shipping it. This isn’t just good hygiene it’s what makes debugging possible and auditing feasible.
- Retraining strategy. Models need to be retrained. The question is when and how. Scheduled retraining on a fixed cadence? Triggered retraining when drift is detected? Both? The right answer depends on the use case, the cost of retraining, and how quickly the underlying data distribution changes. Getting this wrong means either wasting compute or running stale models.
What Good MLOps Consulting Looks Like in Practice
At instinctools.com, MLOps consulting services start with the production reality, not the ideal architecture.
The ideal architecture is always the same fully automated pipelines, comprehensive monitoring, clean model registry, continuous retraining. The reality is always messier legacy systems, data quality issues, teams with mixed skill sets, infrastructure that grew organically without a plan.
Good consulting meets the team where they are. Identifies the highest-leverage gaps first. Builds toward the ideal incrementally, with each improvement delivering value before the next one begins.
The teams that get the most out of MLOps consulting are the ones that have at least one model in production and are feeling the pain of maintaining it. Not teams still in the research phase. Not teams who haven’t deployed yet. Teams who know the problem is real because they’re living it.
The Build vs. Buy vs. Consult Question
Most teams trying to improve their MLOps posture face this question eventually.
- Build internally: Possible if you have senior ML engineers with production experience and the time to invest. Rare combination. Usually underestimated in terms of scope.
- Buy a platform: Tools like MLflow, Kubeflow, SageMaker, Vertex AI, and others handle significant parts of the MLOps stack. None of them handle all of it, and the integration work is non-trivial. Platform selection matters and getting it wrong is expensive.
- Bring in consulting: Fastest path to production-grade MLOps if the consultants have done it before. The risk is knowledge transfer making sure the capability stays with the team after the engagement ends, not just with the consultants.
The honest answer for most teams: some combination of all three. The right platform for your use case, external help to implement it properly and build the surrounding practices, and internal ownership of the result.
Who Needs MLOps Consulting Services
| Situation | Consulting Fit |
|---|---|
| Models in production with no monitoring | Strong – the risk is live right now |
| Retraining is manual and ad hoc | Strong – this will break at the worst time |
| Can’t reproduce models that are in production | Strong – governance and audit risk |
| Data scientists doing their own deployments | Medium – process and tooling gaps likely |
| First ML deployment coming up | Medium – better to build right than retrofit |
| Still in research / pre-production | Weak – too early for most MLOps investment |
The notebook is not the product. The production system is the product. And building a production ML system that’s reliable, monitored, and maintainable requires a different set of skills and practices than building a model that scores well on a test set.
MLOps consulting services exist because that gap is real, consequential, and a lot harder to close from the inside than it looks from the outside.
The models that are still running cleanly a year after deployment aren’t there by accident. Someone built the infrastructure around them properly. That work is unglamorous, invisible when it’s done right, and completely obvious when it isn’t.